Technische Grundlagen
Kursinhalte
- VS Code
- PowerShell, zsh, bash
- Interpreter, pip & venv
- Git, GitHub & Gitflow
- Übungsaufgabe
Entwicklungsumgebung einrichten: VS Code, Terminal, venv & GitHub
Visual Studio Code – Programmierumgebung (Editor)

Visual Studio Code (kurz: VS Code) ist ein kostenloser, plattformunabhängiger Code-Editor, der von Microsoft entwickelt wurde. Er eignet sich nicht nur für Webentwicklung, sondern ist auch hervorragend für Python-Projekte, Datenanalyse, wissenschaftliches Rechnen und KI-Anwendungen geeignet. Durch seine Erweiterbarkeit und die integrierte Terminal- und Git-Unterstützung ist VS Code eine beliebte Wahl für Einsteiger und Profis gleichermaßen.
Funktionen im Überblick:
- Syntaxhervorhebung für viele Sprachen: z. B. HTML, CSS, JavaScript, Python, C++, Markdown
- Live-Vorschau von Webseiten (mit Erweiterung)
- Integrierte Git-Unterstützung: Commit, Push, Pull direkt im Editor
- Erweiterungen für:
- KI-gestützte Codevervollständigung (z. B. IntelliCode, Copilot)
- Debugging mit Breakpoints und Variableninspektion
- Jupyter Notebooks direkt in VS Code
- Paketverwaltung und virtuelle Umgebungen
- Integriertes Terminal: PowerShell, bash, zsh oder eigene Shells direkt im Editor
- Flexible Interpreterwahl: z. B. System-Python oder venv
- Plattformübergreifend: läuft auf Windows, macOS und Linux
Phase 1: Das Werkzeug – Download & Installation
Download des Editors:
Um mit Visual Studio Code zu arbeiten, muss das Programm zunächst heruntergeladen, installiert und für die Python-Entwicklung eingerichtet werden – einschließlich der passenden Erweiterung, der Auswahl eines Interpreters und der Konfiguration des Terminals. Der Download erfolgt über die offizielle Website code.visualstudio.com, wo du dein Betriebssystem (Windows, macOS oder Linux) auswählst. Anschließend lädst du den entsprechenden Installer herunter und folgst den Installationsanweisungen, um VS Code auf deinem Rechner einzurichten.

Wichtiger Hinweis zum Verständnis: VS Code ist dein Werkzeugkasten, nicht der Handwerker. Du organisierst, schreibst und steuerst deinen Code darin – aber ausgeführt wird er vom Python-Interpreter.
Sobald du den Installer ausgeführt hast, kannst du Visual Studio Code öffnen.“
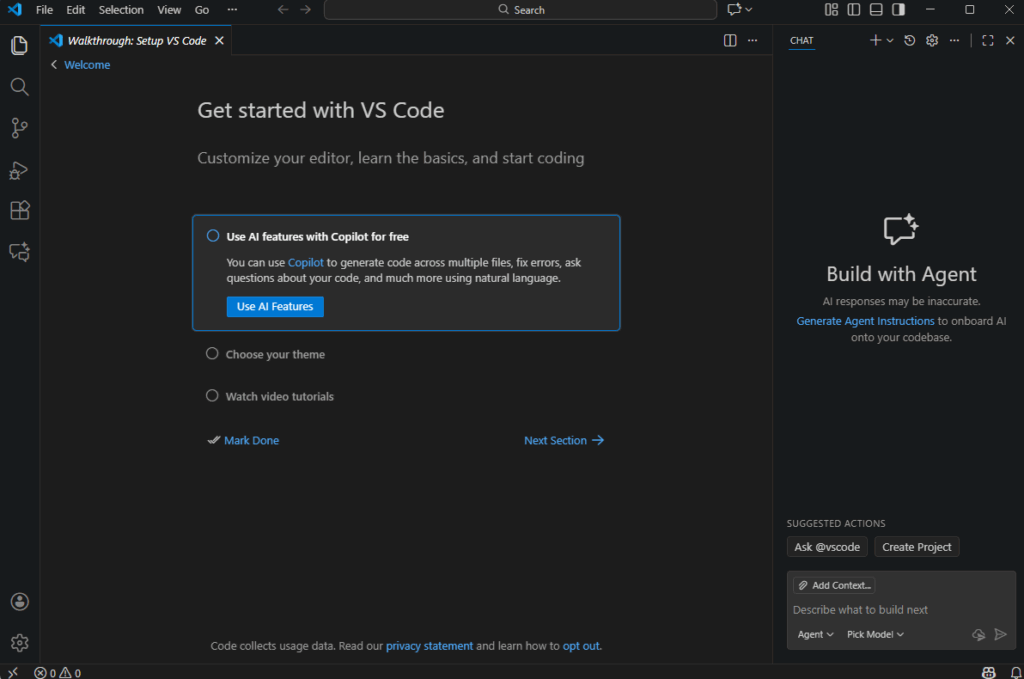
Beim ersten Start von Visual Studio Code nach einem Update oder einer Neuinstallation erscheint oft ein Willkommensfenster mit dem Hinweis auf „AI Features mit Copilot kostenlos nutzen“. Wenn du dort auf „Use AI Features“ klickst, wird:
- die Copilot-Erweiterung installiert (falls noch nicht vorhanden),
- dein VS Code mit deinem GitHub-Konto verbunden (für Authentifizierung),
- und du erhältst Zugriff auf Funktionen wie:
- Code-Vervollständigung über mehrere Dateien hinweg,
- Fehlererkennung und -behebung,
- Fragen zum Code stellen (z. B. „Was macht diese Funktion?“),
- natürliche Sprache zur Codegenerierung nutzen.
Diese Einbindung ist optional und kann jederzeit manuell erfolgen.
Python unter Windows installieren
Lade Python von der offiziellen Website herunter (python.org) und starte den Installer.
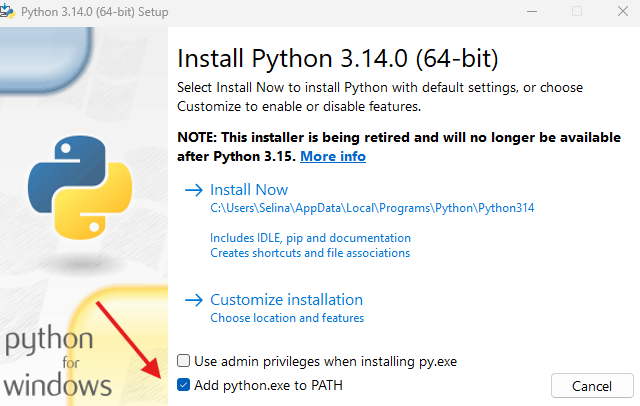
Wichtig: Im ersten Installationsfenster musst du den Haken bei „Add Python to PATH“ setzen. Nur so erkennt dein System Python korrekt – andernfalls kann VS Code Python nicht ausführen.
Überprüfung der Python-Installation unter Windows
- Terminal öffnen
Win + Rdrücken →cmdeingeben → Enter.- Es öffnet sich die Eingabeaufforderung.
- Version abfragenCode
python --versionoderCodepy --version - Ergebnis prüfen
- Wenn eine Versionsnummer erscheint (z. B.
Python 3.13.0), ist alles korrekt installiert und im PATH eingetragen. - Wenn eine Fehlermeldung kommt („wird nicht erkannt“), fehlt der PATH-Eintrag oder Python wurde nicht installiert.
- Wenn eine Versionsnummer erscheint (z. B.
- Tipp
- Falls es nach der Installation nicht sofort klappt, einmal VS Code/Terminal neu starten oder den PC neu starten.
- Danach erneut testen.
Installation der Python-Erweiterungen:

- Öffne VS Code und klicke auf das Erweiterungen-Symbol (vier kleine Quadrate links). Suche nach „Python“ und installiere die offizielle Erweiterung von Microsoft. Diese Erweiterung macht VS Code zu einer vollwertigen Python-Entwicklungsumgebung:
- automatische Interpreter-Erkennung
- Syntax-Highlighting und Fehleranzeige
- Codeausführung und Debugging
- Integration von Jupyter Notebooks
- Verwaltung virtueller Umgebungen
Nur wenn beide Schritte erledigt sind, kannst du Python-Dateien in VS Code schreiben, ausführen und debuggen.
Zusätzlich zur Python-Erweiterung sollten nun weitere hilfreiche Tools in VS Code aktiviert werden – darunter Pylance, Jupyter und ggf. GitHub Copilot, falls dieser nicht bereits im ersten Schritt installiert wurde.
- Pylance:
- Pylance ist eine hochmoderne Erweiterung, die die Sprachunterstützung für Python verbessert. Sie macht das Programmieren effizienter, indem sie dir beim Schreiben von Code hilft, Fehler findet und die Lesbarkeit steigert.
- Funktion: Bietet IntelliSense (intelligente Autovervollständigung), Code-Navigation (springe direkt zur Definition einer Funktion) und eine präzisere Fehlerprüfung (statische Code-Analyse).
- Nutzen: Erhöht die Produktivität und hilft dir, Fehler zu vermeiden, bevor du deinen Code überhaupt ausführst. Pylance ist der de facto Standard für die Python-Entwicklung in VS Code.
- Jupyter:
- Jupyter ist die Erweiterung, die es dir ermöglicht, Jupyter Notebooks direkt in VS Code zu erstellen, anzuzeigen und auszuführen. Notebooks sind für die KI- und Data Science-Arbeit unerlässlich.
- Funktion: Ermöglicht interaktives Programmieren in Zellen. Du kannst Code in einer Zelle ausführen und die Ergebnisse (Variablen, Grafiken, Tabellen) direkt darunter sehen, ohne das gesamte Skript neu starten zu müssen.
- Nutzen: Ideal für experimentelles Coding, Datenanalyse, Visualisierung (z. B. mit Matplotlib) und das Prototyping von Machine Learning-Modellen.
- Du kannst:
- im bestehenden Projektordner arbeiten (praktisch für kleine Projekte).
- einen neuen Ordner anlegen (übersichtlicher für größere Projekte).
- bestehende Notebooks öffnen oder Repos klonen (für Zusammenarbeit oder Vorlagen).
- GitHub Copilot:
- GitHub Copilot ist ein KI-gestütztes Paar-Programmier-Tool, das Code-Vorschläge in Echtzeit direkt in deinem Editor macht.
- GitHub liefert die Basis: Versionsverwaltung, Kollaboration und Projektorganisation.
- Copilot ergänzt diese Umgebung mit intelligenten Code-Vorschlägen in Echtzeit.
- Funktion: Basierend auf deinem bisherigen Code und den Kommentaren, die du schreibst, generiert Copilot ganze Zeilen oder sogar ganze Funktionen als Vorschlag.
- Nutzen: Beschleunigt das Coden massiv, da du oft nur die Tab-Taste drücken musst, um komplexe Code-Muster oder Boilerplate-Code zu übernehmen. Es ist besonders nützlich, um sich wiederholende Aufgaben, Unit-Tests oder Code-Strukturen schnell zu erstellen
Projektstruktur in VS Code einrichten
Nachdem Python erfolgreich installiert und die Erweiterungen aktiviert wurden, kannst du nun dein erstes Projekt starten. Der nächste Schritt ist das Öffnen oder Erstellen eines Projektordners – darin werden deine Python-Dateien gespeichert und verwaltet.
1. „Open Project Folder“ auswählen
- Klicke auf den Button „Open Project Folder“ (oder im Menü: Datei → Ordner öffnen…).
- Es öffnet sich ein Dateiauswahl-Fenster.
2. Neuen Ordner erstellen
- Im Dateiauswahl-Fenster kannst du direkt einen neuen Ordner anlegen.
- Klicke dazu auf „Neuer Ordner“ (unten oder oben, je nach Betriebssystem).
- Gib dem Ordner einen Namen, z. B.
python_projektoderflask_app. - Bestätige mit „Erstellen“.
3. Ordner auswählen und öffnen
- Markiere den neu erstellten Ordner.
- Klicke auf „Ordner auswählen“.
- VS Code öffnet nun diesen Ordner und zeigt ihn links im Explorer-Bereich an.
4. Erste Datei erstellen
- Links im Explorer-Bereich: Rechtsklick auf den Ordner → „Neue Datei“.
- Gib der Datei einen Namen, z. B.
main.pyoderapp.py. - Die Datei erscheint sofort im Explorer und ist bereit für deinen ersten Code.
Phase 2: Das Fundament – Die Shell
Bevor du mit Python arbeitest, solltest du die Umgebung kennen, in der deine Befehle ausgeführt werden: die Kommandozeile, auch Terminal oder Shell genannt. Sie ist ein textbasiertes Interface, über das du direkt mit dem Betriebssystem kommunizierst – zum Beispiel, um Dateien auszuführen, Ordner zu wechseln oder virtuelle Umgebungen zu aktivieren. VS Code enthält ein integriertes Terminal, das dir den Zugriff auf verschiedene Shells wie PowerShell, bash oder zsh direkt im Editor ermöglicht. Alternativ kannst du auch die Eingabeaufforderung (cmd) deines Betriebssystems nutzen. Beide Varianten funktionieren – das integrierte Terminal ist jedoch besonders praktisch, weil du dort Editor und Kommandozeile an einem Ort vereint hast.
So sieht das Windows Terminal aus:
- Welches Terminal für welches Betriebssystem?
- Windows: Du nutzt meist die PowerShell oder die Standard-Eingabeaufforderung.
- macOS und Linux: Du nutzt die zsh (Z Shell) oder Bash.
So sieht das PowerShell-Terminal innerhalb von Visual Studio Code aus:
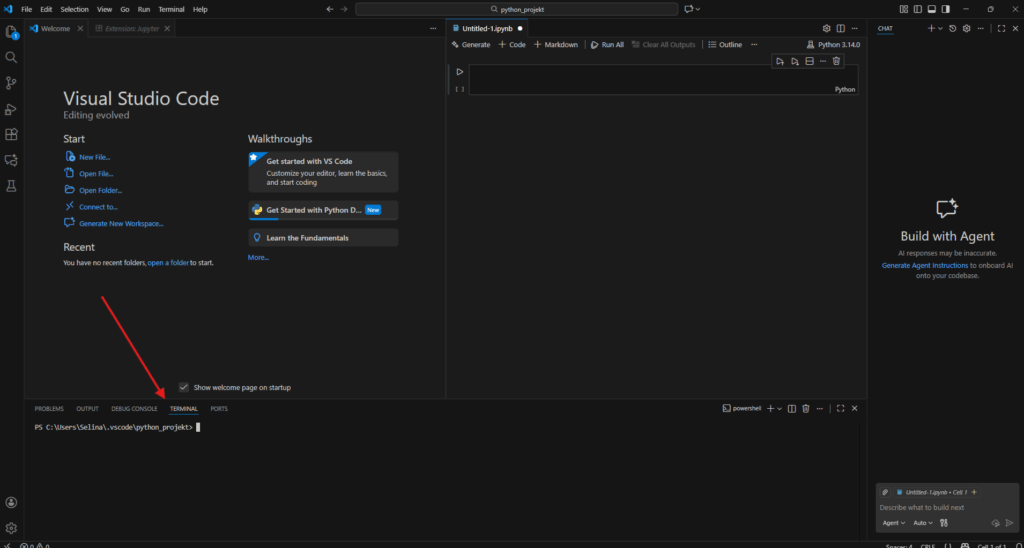
Das integrierte PowerShell-Terminal in Visual Studio Code bietet deutlich mehr Funktionalität und Komfort als die klassische Eingabeaufforderung (CMD). PowerShell unterstützt komplexere Befehle, Skripte und moderne Shell-Funktionen wie Objektverarbeitung, Alias-Namen und integrierte Hilfefunktionen. Besonders bei der Arbeit mit Python, Git oder Paketverwaltung (z. B. pip) ist PowerShell robuster und flexibler. Da es direkt in VS Code eingebettet ist, kannst du nahtlos zwischen Editor und Terminal wechseln – ohne separate Fenster oder Einschränkungen. Für moderne Entwicklungsumgebungen ist PowerShell daher die bessere Wahl.
Phase 3: Die Isolation – pip, venv & Interpreter auswählen
1. pip
- Erklärung der Paketverwaltung (
pip):pipist das Standard-Werkzeug zur Paketverwaltung in Python. Es ermöglicht dir, externe Bibliotheken wie NumPy, Pandas, Matplotlib oder TensorFlow aus dem Python Package Index (PyPI) herunterzuladen und in deiner Umgebung zu installieren.- pip kann Pakete installieren und deinstallieren, Installierte Pakete anzeigen und Abhängigkeiten dokumentieren. z.B.:

- Warum ist
pipwichtig?- Es macht Python modular und erweiterbar – du musst nicht alles selbst programmieren.
- Es ist plattformspezifisch unabhängig – du kannst dieselben Pakete unter Windows, macOS und Linux nutzen.
- Es ist zentral für virtuelle Umgebungen: Pakete werden dort isoliert installiert, ohne das System-Python zu verändern.
In den meisten modernen Python-Versionen (ab Python 3.4) ist pip bereits automatisch enthalten.
Öffne dein Terminal – unter Windows z. B. PowerShell, unter macOS oder Linux zsh oder bash – und gib einen der folgenden Befehle ein, um zu überprüfen, ob pip bei dir bereits installiert ist:
pip --version
# oder
pip3 --version- Wenn eine Versionsnummer angezeigt wird (z. B.
pip 23.3.1 from ...), dann ist pip installiert und einsatzbereit. - Wenn eine Fehlermeldung erscheint (z. B. „Befehl nicht gefunden“), musst du pip möglicherweise manuell installieren oder den Pfad überprüfen.
2. Venv erstellen und Interpreter wählen
- Erklärung und Erstellung der Virtuellen Umgebung (
venv):venvsteht für Virtual Environment (Virtuelle Umgebung) und ist ein Standardwerkzeug in Python, das dir hilft, Projekte voneinander zu isolieren. Stell dirvenvwie eine saubere Projekt-Box vor: Du erstellst sie neu für jedes Vorhaben, und alles, was du darin installierst, bleibt auf dieses Projekt beschränkt.- Python nutzt normalerweise eine zentrale Paketbibliothek. Wenn du mehrere Projekte mit unterschiedlichen Paketversionen betreibst, kann es zu Konflikten kommen – etwa wenn Projekt A eine ältere Version von NumPy braucht, Projekt B aber die neueste.
venvverhindert solche Überschreibungen, indem es:- eine eigene Kopie des Python-Interpreters anlegt,
- eine lokale Paketbibliothek bereitstellt,
- und keinen Einfluss auf dein System-Python nimmt.
- Mit
venvkannst du exakt dokumentieren, welche Pakete und Versionen du verwendest (z. B. viarequirements.txt). Andere können diese Umgebung nachbauen – dein Code läuft dann überall gleich. Das ist essenziell für Clean Code, Teamarbeit und nachvollziehbare Ergebnisse. - Wenn du in VS Code arbeitest, musst du dem Editor mitteilen, welchen Python-Interpreter er verwenden soll. Wählst du den Interpreter aus dem
venv-Ordner, sagst du VS Code:
„Nutze diesen isolierten Prozess – nur die Pakete in dieser Projekt-Box zählen.“
Das ist der Schlüssel für eine saubere, konfliktfreie Projektentwicklung.
Anleitung Erstellung der Virtuellen Umgebung:
1. Terminal öffnen
- In VS Code unten auf den Reiter „Terminal“ klicken
- Du solltest dich bereits im Projektordner befinden
2. Umgebung erstellen
- Öffne dein Terminal im Projektordner und gib ein:
python -m venv env
→ Dadurch wird ein neuer Ordner env mit der virtuellen Umgebung angelegt.
Automatische Erkennung durch VS Code Nach der Erstellung erscheint eine Meldung: „We noticed a new environment has been created. Do you want to select it for the workspace folder?“
- Klicke auf „Yes“.
- VS Code setzt die neue Umgebung automatisch als aktiven Interpreter für dein Projekt.
Interpreter manuell auswählen in VS Code
- Command Palette öffnen
Strg + Umschalt + Pdrücken- Tippe:
Python: Select Interpreter
- Liste der Umgebungen
- Es erscheint eine Liste aller gefundenen Python-Umgebungen.
- Dort sollte auch deine virtuelle Umgebung stehen, z. B.:
Python 3.10.4 ('env': venv)3. Interpreter auswählen
Danach wird sie für dein Projekt gesetzt.
Klicke auf den Eintrag mit deiner Umgebung (env).
3. venv vs. System-Python
In Visual Studio Code werden dir beim Auswählen des Python-Interpreters unterschiedliche Optionen angezeigt – je nachdem, wie dein Projekt aufgebaut ist und welche Python-Installationen VS Code erkennt. In den meisten Fällen erscheint die virtuelle Umgebung (venv), die du zuvor mit dem Befehl python -m venv env erstellt hast. Diese venv enthält eine isolierte Kopie des Python-Interpreters sowie eine eigene, leere Paketbibliothek und wird von VS Code automatisch erkannt und priorisiert, sobald du dich im entsprechenden Projektordner befindest.
Alternativ kann auch der System-Python angeboten werden – das ist die global installierte Python-Version deines Betriebssystems, die unabhängig von einzelnen Projekten funktioniert. VS Code zeigt diesen Interpreter jedoch nur dann aktiv an, wenn keine venv im Projektordner liegt oder wenn die Systeminstallation korrekt erkannt wurde. Häufig wird der System-Python bewusst nicht vorgeschlagen, um Paketkonflikte zwischen verschiedenen Projekten zu vermeiden.
Trotzdem kannst du den System-Interpreter manuell auswählen – zum Beispiel für einfache Skripte außerhalb von Projektordnern oder wenn du bewusst auf globale Pakete zugreifen möchtest.
| Das System-Python | Die Virtuelle Umgebung (venv) |
| Was es ist: Das ist der Python-Interpreter, der auf deinem gesamten Betriebssystem (System) installiert ist und global für alle Programme zugänglich ist. Wann man es wählt: Wenn du an sehr einfachen Projekten arbeitest oder wenn du weißt, dass du keine speziellen Pakete benötigst, die mit anderen Projekten in Konflikt geraten könnten. Nachteil: Wenn du viele Projekte mit unterschiedlichen Paketversionen hast, führt die Verwendung des System-Python oft zu Konflikten. | Was es ist: Die venv ist ein isolierter Ordner, der seine eigene Kopie des Interpreters und seine eigene, leere Bibliothek an Paketen enthält.Wann man es wählt: Bei fast allen professionellen oder komplexeren Projekten. Vorteil: Durch die Auswahl der venv wählst du den isolierten Interpreter aus. VS Code weiß dann: „Führe den Code nur mit den Paketen aus, die in dieser Projekt-Box sind.“ Das stellt sicher, dass dein Projekt immer funktioniert, unabhängig davon, welche Pakete du für andere Projekte global installiert hast. |
Fazit:
Die Wahl der virtuellen Umgebung (venv) ist der Standard und die empfohlene Vorgehensweise, um Konflikte zu vermeiden und dein Projekt sauber zu halten.
Phase 4: Der Code-Ausführer – Kernel & Interaktivität
Sobald du in VS Code einen Python-Interpreter ausgewählt hast – z. B. aus deiner virtuellen Umgebung (venv) – stellt sich die nächste Frage: Wie genau wird dein Code ausgeführt? Das hängt davon ab, ob du in einer normalen .py-Datei arbeitest oder in einem Jupyter Notebook.
- Was ist der Interpreter?
- Der Interpreter ist das Programm, das deinen Python-Code Zeile für Zeile in Maschinensprache übersetzt und ausführt. Technisch gesehen ist es eine ausführbare Datei – z. B.
python.exeunter Windows oderpython3unter macOS/Linux. - In
.py-Dateien wird der Code direkt über diesen Interpreter ausgeführt. - In virtuellen Umgebungen gibt es für jedes Projekt eine eigene Interpreter-Datei – das sorgt für Isolation.
- Der Interpreter ist das Programm, das deinen Python-Code Zeile für Zeile in Maschinensprache übersetzt und ausführt. Technisch gesehen ist es eine ausführbare Datei – z. B.
- Was ist der Kernel?
- Der Kernel ist ein laufender Python-Prozess, der speziell für interaktive Umgebungen wie Jupyter Notebooks gedacht ist. Er ermöglicht dir:
- Code Zelle für Zelle auszuführen
- Zwischenergebnisse zu behalten (z. B. Variablen, Datenframes)
- Visualisierungen inline darzustellen
mit dem Kernel zu kommunizieren, z. B. durch Stoppen, Neustarten oder Wechseln - Man kann sagen: Der Interpreter ist das Werkzeug, das den Code ausführt – der Kernel ist der aktive Zustand dieses Werkzeugs im interaktiven Modus.
- Wie funktioniert das in VS Code mit Jupyter?
- Wenn du ein Jupyter Notebook (
.ipynb) in VS Code öffnest: - VS Code erkennt automatisch den Interpreter, den du vorher ausgewählt hast (z. B. aus deiner venv).
- Dieser Interpreter wird als Kernel gestartet – also als laufender Prozess.
- Du kannst nun Zelle für Zelle ausführen, und der Kernel merkt sich alle bisherigen Ausgaben und Variablen.
- Alle Pakete, die du in deiner venv installiert hast, stehen dir im Notebook zur Verfügung.
- Wenn du ein Jupyter Notebook (
- Ergebnis: Kontrolle & Reproduzierbarkeit
- Durch diese Verbindung von Interpreter (aus venv) und Kernel (für interaktive Ausführung) kannst du sicher sein, dass:
- dein Code in der richtigen Umgebung läuft,
- du nur die Pakete verwendest, die du selbst installiert hast,
- und dein Notebook auf anderen Rechnern genauso funktioniert, wenn dort dieselbe venv eingerichtet ist.
Aufgabe – Erste Datei erstellen & testen
- Lege eine neue Datei an:
main.py - Schreibe z. B.:
print("Hallo VS Code") - Führe sie aus:
- Rechtsklick → „Python-Datei im Terminal ausführen“
- oder Terminal:
python main.py
Vokabeln
Kernel
Der Begriff Kernel bedeutet wörtlich „Kern“ und hat in der Informationstechnologie je nach Anwendungsgebiet eine unterschiedliche, aber stets zentrale Bedeutung als Kontrollinstanz oder Ausführungsebene.
Verschiedene Anwendungen des Begriffs „Kernel“
- Betriebssystem-Kernel (OS): Dies ist der bekannteste Kern des Betriebssystems (wie Windows, Linux oder macOS). Seine Hauptaufgabe ist die Verwaltung der gesamten Hardware (CPU, Speicher, Festplatten und Netzwerk) und die Vermittlung zwischen den laufenden Programmen und diesen Hardware-Ressourcen. Er ist das unverzichtbare Fundament, das die Ausführung aller Software erst ermöglicht.
- Jupyter-/Python-Kernel: Im Bereich Data Science und bei der Nutzung von Notebooks (z. B. in VS Code oder Jupyter) ist der Kernel der laufende Python-Prozess, der deinen Code im Notebook ausführt. Er ist fest an eine konkrete Python-Umgebung (wie eine virtuelle Umgebung oder Conda) gebunden. Fehlen notwendige Pakete, liegt es oft daran, dass diese in einer anderen Umgebung installiert wurden, als die, die der aktuelle Kernel verwendet.
- Maschinelles Lernen (ML-Kernel): Bei bestimmten Algorithmen wie Support Vector Machines (SVM) bezeichnet der Kernel eine mathematische Ähnlichkeitsfunktion. Diese Funktion hilft dabei, Daten in höherdimensionale Räume zu transformieren, um sie leichter klassifizieren oder trennen zu können.
- GPU-Kernel (seltener): Im Kontext von paralleler Datenverarbeitung (z. B. CUDA oder OpenCL) ist ein GPU-Kernel eine Funktion oder ein Programmteil, der gleichzeitig auf vielen Kernen der Grafikkarte ausgeführt wird, um Berechnungen massiv zu beschleunigen.
Git – Versionskontrolle für Code

Was ist Git? Git ist ein Versionsverwaltungssystem, das es ermöglicht, Änderungen am Code nachvollziehbar zu speichern. Es funktioniert wie ein digitales Tagebuch für dein Projekt – jede Änderung wird als sogenannter Commit festgehalten.
Git installieren und mit VS Code verbinden
Voraussetzungen
- Windows: Administratorrechte für die Installation
- VS Code: Bereits installiert
- Internet: Für Download und ggf. GitHub-Verbindung
Git installieren

- Download starten
- Gehe zu: https://git-scm.com
- Klicke auf Download for Windows.
- Setup ausführen
- Starte die heruntergeladene
.exe. - Wähle die Standardoptionen; das ist für die meisten Nutzer ideal.
- Starte die heruntergeladene
- Wichtige Installer-Option
- Achte darauf, dass „Git from the command line and also from 3rd-party software“ (Git zur PATH-Variablen hinzufügen) aktiviert ist.
- So erkennt das Terminal den
git-Befehl überall.
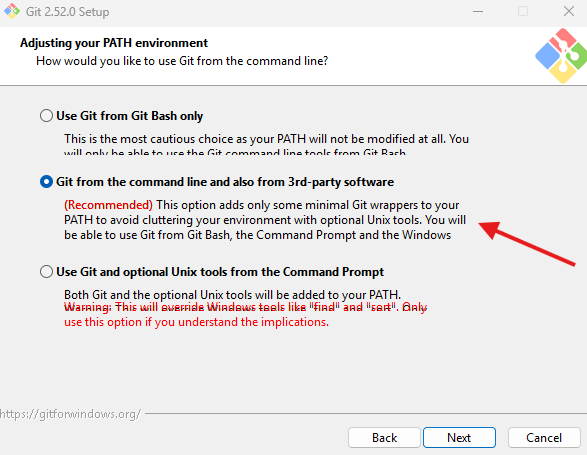
- Installation abschließen
- Klicke dich durch den Installer bis Finish.
- Optional: „Git Bash“ installieren lassen (praktische Shell für Git-Befehle).
- Installation prüfen
- Öffne VS Code neu.
- Öffne Terminal: Ansicht → Terminal.
- Tippe:
git --versionErwartung: Eine Versionsnummer erscheint (z. B. git version 2.x).

Git in VS Code aktivieren und prüfen
- Projektordner öffnen
- Datei → Ordner öffnen → Wähle deinen Projektordner.
- Quellcodeverwaltung prüfen
- Klicke links auf das Source Control-Icon (Verzweigungs-Symbol).
- Wenn Git aktiv ist, siehst du Änderungen/Status; sonst ist es leer.
- Repository initialisieren
- Öffne Terminal und führe aus:
git init- VS Code erkennt jetzt das Repo; die Statusleiste zeigt den Branch (z. B.
main).
Oder:
Klicke links in der Seitenleiste auf das Symbol für Source Control (Verzweigungs-Icon). Dann siehst du folgendes:
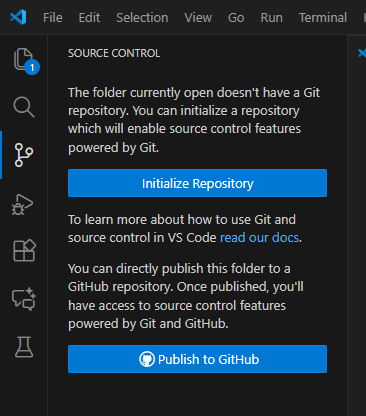
Klicke auf „Initialize Repository“
So prüfst du ob der Schritt funktioniert hat:
git status- Wenn dein Ordner ein Repository ist, bekommst du eine Ausgabe wie: „On branch main“ und eine Liste geänderter Dateien.
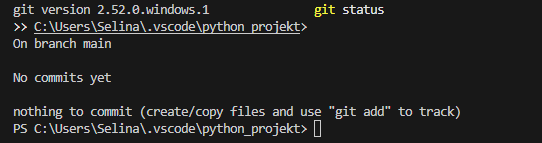
- Wenn kein Repository existiert, erscheint: „fatal: not a git repository (or any of the parent directories): .git“
4. Identität konfigurieren
- Setze deinen Namen und deine E-Mail (für Commits):
git config --global user.name "Vorname Nachname"
git config --global user.email "deine@email.de"Um diesen Schritt zu überprüfen, kannst du im Terminal folgendes eingeben:
git config --global --listErste Version sichern (Initial Commit)
- Dateien vormerken
git add .2. Commit erstellen
git commit -m "Initial commit"3. Status kontrollieren
git statusErwartung: Arbeitsverzeichnis sauber, keine uncommitted changes.
Mit GitHub verbinden
Remote-Repository anlegen
Auf GitHub: Neues Repository erstellen (ohne README, wenn lokal schon Dateien existieren).
Diese Dateien kannst du später lokal hinzufügen und hochladen.
Was ist ein Repository?
Ein Repository (kurz: Repo) ist ein Projektordner, den Git verwaltet.
- Es enthält alle Dateien deines Projekts (Code, Dokumentation, Bilder usw.).
- Zusätzlich gibt es einen versteckten
.git-Ordner, in dem die Versionsgeschichte gespeichert wird. - Damit kannst du jederzeit nachvollziehen, welche Änderungen gemacht wurden, und ältere Stände wiederherstellen.
- Ein Repository kann lokal (auf deinem PC) oder remote (z. B. auf GitHub) existieren.
Du kannst dir ein Repository wie eine „Projekt-Box mit Zeitmaschine“ vorstellen: Alles, was du hineinlegst, wird versioniert und kann zurückgespult werden.
Neues Repository auf GitHub erstellen
Wenn du dein Projekt nicht nur lokal, sondern auch online sichern oder teilen willst, legst du ein Remote-Repository auf GitHub an.
Schritte:
- Gehe auf GitHub und melde dich an.
- Klicke oben rechts auf „+“ → New repository.
- Gib einen Namen für dein Projekt ein (z. B.
python_projekt). - Wichtig:
- Wenn du lokal schon Dateien hast, kein README, keine .gitignore, keine License auswählen.
- Sonst kollidieren die Inhalte beim ersten Push.
- Klicke auf Create repository.
- Jetzt hast du ein leeres Remote-Repo, das bereit ist, mit deinem lokalen Projekt verbunden zu werden.
2. Remote hinzufügen
git remote add origin https://github.com/<dein-user>/<dein-repo>.git3. Branch benennen
git branch -M main4. Push durchführen
git push -u origin mainBeim ersten Push meldet sich VS Code/Git mit einem Login/Token-Dialog.
Ergebnis:
- Dein Projekt ist lokal in VS Code und gleichzeitig online auf GitHub verfügbar.
- Änderungen kannst du künftig mit
git add,git commitundgit pushhochladen.
Sichtbare Bestätigungen in VS Code
- Statusleiste: Aktueller Branch-Name (z. B.
main). - Source Control-Panel: Auflistung geänderter Dateien und Commit-Buttons.
- Terminal-Befehle:
git status,git logliefern sinnvolle Ausgaben.
Troubleshooting
- „git nicht gefunden“: VS Code neu starten; wenn weiterhin, Git neu installieren und sicherstellen, dass PATH gesetzt ist.
- Kein Branch sichtbar:
git initim richtigen Ordner ausführen und Datei anlegen/committen. - Auth-Probleme bei GitHub: In VS Code „Konten“ prüfen (Profil-Icon), ggf. GitHub anmelden und Personal Access Token nutzen.
Die Notwendigkeit der Versionskontrolle – Warum Branches, Pushes und Merges unverzichtbar sind
In der Softwareentwicklung ist es eine Seltenheit, dass ein Entwickler allein und isoliert an einem Projekt arbeitet. Sobald Projekte eine bestimmte Größe erreichen oder in Teams entwickelt werden, entstehen unweigerlich technische Herausforderungen, die ohne ein robustes System zur Versionskontrolle und Zusammenarbeit schnell unüberwindbar werden:
- Das Problem der parallelen Entwicklung:
- Stell dir vor, du und dein Kollege arbeiten beide gleichzeitig an derselben Python-Datei. Du fügst eine neue Funktion hinzu, während dein Kollege einen Fehler in einer anderen Funktion dieser Datei behebt. Wenn ihr eure Änderungen einfach blind abspeichert, überschreibt einer von euch unweigerlich die Arbeit des anderen. Wie stellt man sicher, dass beide Änderungen erhalten bleiben und miteinander kompatibel sind, ohne manuelle und fehleranfällige Kopier-/Einfüge-Operationen?
- Das Problem der Code-Stabilität und des Experimentierens:
- Die Hauptversion eines Projekts (z.B. die Version, die beim Kunden läuft oder die in Produktion ist) muss immer stabil und funktionsfähig sein. Wenn du eine experimentelle neue KI-Architektur testen möchtest oder eine größere Code-Refaktorierung vornimmst, die potenziell Fehler enthalten könnte, darf das nicht den stabilen Hauptcode beeinträchtigen. Wie kann man neue Features oder Fehlerbehebungen entwickeln, ohne das Risiko einzugehen, den funktionierenden Code zu zerstören?
- Das Problem der Koordination und Freigabe:
- Wenn jeder Entwickler seine Änderungen einfach in ein zentrales Verzeichnis lädt, wie behält man dann den Überblick? Wer hat welche Änderung wann gemacht? Und wie wird sichergestellt, dass neue Funktionen gründlich getestet und von anderen Teammitgliedern überprüft werden, bevor sie Teil der „offiziellen“ Version werden?
Genau diese fundamentalen Probleme löst das Versionskontrollsystem Git in Kombination mit einer Plattform wie GitHub. In diesem Block lernst du die Kernmechanismen kennen, die diese Koordination und Sicherheit gewährleisten und dich zu einem effizienten Teammitglied machen:
- Branches: Schaffen isolierte Entwicklungsumgebungen.
- Pushes: Übertragen deine isolierte Arbeit sicher in ein zentrales Repository.
- Merges: Führen deine getesteten Änderungen kontrolliert und nachvollziehbar mit der Arbeit deines Teams zusammen.
Diese Konzepte sind die technische Grundlage für effiziente und fehlerarme Softwareentwicklung im Team. Sie ermöglichen es uns, komplexe Projekte zu managen, Qualität zu sichern und gleichzeitig agil zu bleiben.
Warum ist Git wichtig?
- Du kannst jederzeit zu einer früheren Version zurückkehren
- Du siehst, wer was geändert hat (ideal für Teamarbeit)
- Du kannst experimentieren, ohne etwas zu verlieren
- Du arbeitest strukturiert und professionell
Typische Befehle:
git init # Neues Git-Repository starten
git add . # Änderungen vormerken
git commit -m "Beschreibung" # Änderungen speichernGrundkonzepte von Git
Während die tägliche Arbeit mit Git oft über klare Befehle (wie commit, push, pull) und visuelle Workflows (wie Branches und Merges) abläuft, steckt dahinter ein elegantes und leistungsstarkes System. Um Git wirklich zu verstehen, Fehler effizient zu beheben und seine volle Kraft auszuschöpfen, ist es hilfreich, einen Blick unter die Haube zu werfen. Dieser Abschnitt beleuchtet die Kernkonzepte, die Git intern zur Verwaltung deiner Code-Historie und zur Realisierung seiner Funktionalität nutzt. Wir werfen einen Blick auf die „Bausteine“, aus denen Git seine komplexe Arbeitsweise aufbaut.
- Pointer (Zeiger): Git nutzt Pointer (Zeiger), die auf bestimmte Commits zeigen. Diese sind entscheidend für die Navigation und das Verständnis des Projektzustands.
- Der wichtigste ist HEAD → zeigt auf den aktuell aktiven Commit (also den Commit, an dessen Spitze sich deine aktuelle Arbeitskopie befindet).
- Wird der
HEADverschoben (z.B. durch Wechseln eines Branches oder Zurücksetzen auf einen früheren Commit), passt Git die Arbeitskopie automatisch an, um den Codezustand des referenzierten Commits anzuzeigen.
- Tags: Tags sind feste Pointer, die bestimmten Commits einen dauerhaften, sprechenden Namen geben – z. B.
v1.0.0für eine Softwareversion.- Im Gegensatz zu Branch-Pointern (siehe nächster Punkt) sind Tags statisch und bewegen sich nicht mit neuen Commits. Sie sind wie unveränderliche Lesezeichen in der Projektgeschichte.
- Nützlich für Versionierung und Wiederauffindbarkeit: Sie dienen dazu, wichtige Punkte in der Historie zu markieren, wie z.B. die Veröffentlichung einer stabilen Softwareversion, auf die man sich später immer wieder beziehen kann.
- Branch-Pointer: Branch-Pointer sind bewegliche Zeiger, die einem Branch folgen.
- Jeder Branch in Git ist intern nicht viel mehr als ein solcher Pointer, der auf den neuesten Commit in diesem Zweig zeigt.
- Mit jedem neuen Commit, den du auf einem Branch machst, „wandert“ der Branch-Pointer automatisch zum neuen Commit vor.
- Dies erlaubt das schnelle und effiziente Wechseln zwischen Entwicklungszweigen, da Git nur den
HEADund den entsprechenden Branch-Pointer neu ausrichten muss, um deine Arbeitskopie anzupassen.
- Repository & Arbeitskopie: Git organisiert deine Projektdateien in zwei eng verbundenen Bereichen:
- Repository: Dies ist der gesamte Datenspeicher von Git. Es speichert alle Commits, Branches, Tags und die komplette Historie deines Projekts. Das Repository liegt lokal in dem versteckten
.git-Ordner innerhalb deines Projektverzeichnisses. - Arbeitskopie (Working Directory): Dies sind die aktuellen Dateien und Ordner, mit denen du direkt arbeitest und die du in deinem Editor siehst. Es ist der aktuelle Zustand, der aus dem vom
HEADreferenzierten Commit „ausgecheckt“ wurde. - Da das Repository lokal auf deinem Rechner liegt, kann Git dadurch schnell und offline arbeiten. Alle Operationen wie Commits, Branches wechseln oder Historie ansehen sind sofort verfügbar, ohne dass eine Internetverbindung benötigt wird.
- Repository: Dies ist der gesamte Datenspeicher von Git. Es speichert alle Commits, Branches, Tags und die komplette Historie deines Projekts. Das Repository liegt lokal in dem versteckten
Der Git-Workflow im Detail

- Git Command:
- Git Command (oder Git-Befehl) ist der Überbegriff für alle Anweisungen, die du dem Versionskontrollsystem Git gibst, um Aktionen auszuführen.
- Zweck: Git-Befehle sind die Schnittstelle zwischen dir und dem Git-System. Sie ermöglichen es dir, das Repository zu manipulieren, den Status abzufragen, Änderungen zu speichern, Branches zu wechseln und mit Remote-Repositories zu interagieren.
- Beispiele:
git commit,git push,git pull,git branch,git merge,git clonesind allesamt Git-Befehle. - Im Bild ist
GIT COMMANDals zentrales Element auf dem Laptop platziert. Dies symbolisiert, dass alle Interaktionen mit Git über diese Befehle auf deinem lokalen System gesteuert werden. Die grafische Oberfläche (wie der Code-Editor) ist nur eine Visualisierung deiner Arbeit; die eigentliche Versionskontrolle erfolgt über die Git-Befehle.
- Commit:
- Commit Ein Commit ist die kleinste Einheit in Git und speichert eine Gruppe von Änderungen.
- Enthält nur die Differenz zum vorherigen Zustand, nicht das ganze Projekt.
- Jeder Commit bekommt einen sicheren Hash-Wert, der auch den vorherigen Commit referenziert. So entsteht eine unveränderliche Historie – wie ein Kettenbuch.
- Im Bild repräsentieren die Kreise und Punkte auf den Linien einzelne Commits. Der Befehl
COMMITauf dem Laptop führt einen solchen Commit aus.
- Branch (Zweig)
- Ein Branch ist eine alternative Entwicklungslinie.
- Startet von einem bestehenden Commit.
- Ideal für Experimente oder neue Features, ohne den Hauptcode zu beeinträchtigen.
- Die Historie wird zu einem verzweigten Baum.
- Der Befehl
BRANCHim Bild zeigt das Abzweigen einer neuen Entwicklungslinie von der Hauptlinie
- Remote
- Das Remote-Repository ist ein zentraler Speicherort für dein Git-Projekt, der sich nicht auf deinem lokalen Rechner befindet (z.B. auf GitHub, GitLab oder einem eigenen Server).
- Zweck: Dient als zentrales Backup und als Koordinationspunkt für Teams. Alle Entwickler synchronisieren ihre lokalen Repositories mit diesem Remote.
- Verbindung: Dein lokales Git-Repository „kennt“ das Remote-Repository. Standardmäßig wird es oft als
originbezeichnet. - Im Bild steht
REMOTEfür diesen externen Speicherort, der die „Cloud“ oder den „Server“ des Projekts darstellt.
- Push
- Push ist der Vorgang, bei dem du deine lokalen Commits von deinem Computer in das Remote-Repository überträgst („hochlädst“).
- Zweck: Macht deine lokalen Änderungen für andere Teammitglieder sichtbar und zugänglich. Es ist der Weg, deine Arbeit zu teilen und zu sichern.
- Sicherheitskontrolle: Git prüft vor dem Push, ob deine lokale Historie mit der Remote-Historie übereinstimmt. Du kannst nur „pushen“, wenn deine Änderungen keine Konflikte mit bereits vorhandenen Remote-Änderungen verursachen (oder du musst diese vorher
pullen). - Der Befehl
PUSHim Bild zeigt die Bewegung deiner lokalen Änderungen hin zumREMOTE-Repository.
- Pull
- Pull ist der Vorgang, bei dem du die neuesten Commits und Änderungen vom Remote-Repository auf deinen lokalen Computer herunterlädst und in deine aktuelle Arbeitskopie integrierst.
- Zweck: Stellt sicher, dass dein lokales Repository auf dem neuesten Stand ist und du die Arbeit deiner Teamkollegen in deinem Projekt hast. Dies ist unerlässlich für die Zusammenarbeit.
- Zwei Schritte in einem: Ein
pullist eigentlich eine Kombination ausfetch(Lade die neuen Daten herunter) undmerge(integriere sie in deinen lokalen Branch). - Der Befehl
PULLim Bild zeigt die Bewegung der Änderungen vomREMOTE-Repository zu deinem lokalen Arbeitsbereich.
- Merge
- Merge (Zusammenführen) ist der Prozess, bei dem die Änderungen von einem Branch in einen anderen Branch integriert werden.
- Zweck: Bringt die in einem separaten Branch entwickelte Funktion oder Fehlerbehebung zurück in den Hauptentwicklungszweig (z.B.
mainoderdevelop). - Konfliktlösung: Wenn derselbe Code in beiden Branches unterschiedlich geändert wurde, können Merge-Konflikte entstehen. Git markiert diese Stellen, und du musst manuell entscheiden, welche Änderungen beibehalten werden sollen.
- Der Befehl
MERGEim Bild zeigt, wie eine abzweigende Linie (ein Branch) wieder mit einer anderen Linie (z.B. dem Haupt-Branch) verschmilzt, um die Änderungen zu integrieren.
- Clone
- Clone ist der Vorgang, bei dem du eine vollständige Kopie eines bestehenden Remote-Repositories auf deinen lokalen Computer herunterlädst.
- Zweck: Dies ist der erste Schritt, um an einem bestehenden Git-Projekt zu arbeiten, das sich auf GitHub oder einer ähnlichen Plattform befindet.
cloneerstellt sowohl die Arbeitskopie als auch das lokale.git-Repository. - Im Bild steht
CLONEam unteren Rand des Remote-Baums und deutet an, dass ein Projekt von dort als Ganzes heruntergeladen wird, um lokal damit arbeiten zu können.
GitHub – Online-Plattform zur Codeverwaltung

Was ist GitHub? GitHub ist eine Webplattform, auf der Git-Projekte online gespeichert, geteilt und gemeinsam bearbeitet werden können. Es ist wie ein digitales Klassenzimmer für Code.
Funktionen:
- Online-Backup deiner Projekte
- Zusammenarbeit mit anderen Entwickler:innen
- Versionsverlauf und Kommentarfunktion
- Veröffentlichung von Webseiten über GitHub Pages
Hinweis:
- GitHub basiert komplett auf Git – es ist sozusagen ein „Hub“ für Git-Repositories
- Der Name zeigt: GitHub ist ein zentraler Ort, an dem Git-Projekte gespeichert, geteilt und gemeinsam bearbeitet werden können
- Du kannst Git auch ohne GitHub verwenden (z. B. lokal oder mit anderen Plattformen wie GitLab oder Bitbucket)
- GitHub macht Git visuell, kollaborativ und online verfügbar
Typischer Workflow:
git remote add origin https://github.com/username/projekt.git
git push -u origin mainGitflow – Strukturierte Versionsverwaltung mit Branches
Was ist Gitflow?
Gitflow ist ein strukturiertes Workflow-Modell, das auf Git basiert und die Softwareentwicklung in klar definierte Phasen unterteilt. Es hilft Teams, ihre Arbeit zu organisieren, parallele Entwicklungen zu koordinieren und stabile Releases zu gewährleisten.
Statt alle Änderungen direkt in einen Haupt-Branch zu schreiben, nutzt Gitflow spezialisierte Branches für unterschiedliche Aufgaben: neue Features, Release-Vorbereitung und Fehlerbehebung. Dadurch entsteht eine übersichtliche, nachvollziehbare Versionsgeschichte, die besonders bei größeren Projekten mit mehreren Entwickler:innen von Vorteil ist.
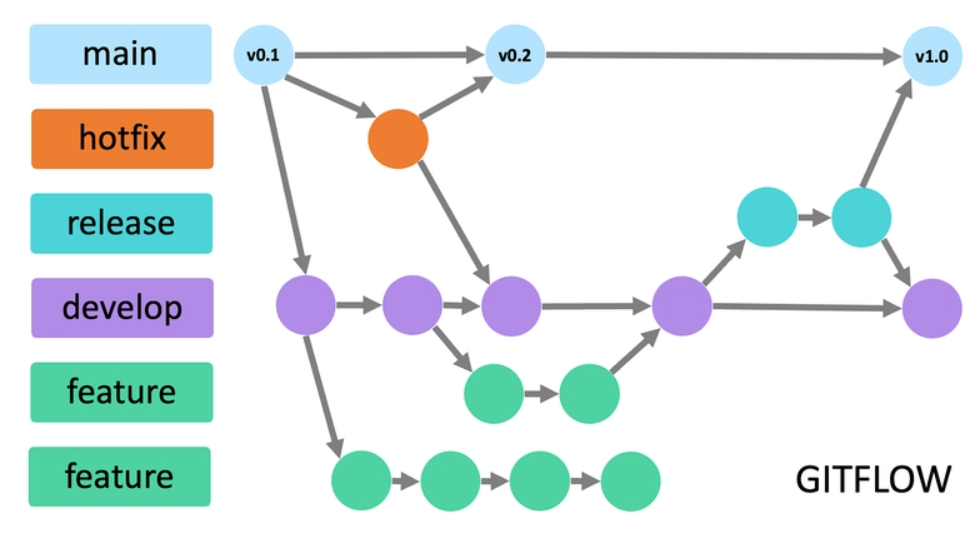
Branch-Typen und ihre Funktionen
| Branch | Funktion |
|---|---|
main | Enthält die stabile, veröffentlichte Version des Projekts. Nur getestete Releases landen hier. |
develop | Der zentrale Entwicklungszweig. Hier werden neue Features integriert und getestet. |
feature/* | Temporäre Branches für neue Funktionen. Sie entstehen aus develop und fließen nach Fertigstellung dorthin zurück. |
release/* | Dient der Vorbereitung eines Releases: letzte Tests, Dokumentation, kleinere Bugfixes. Wird später in main und develop gemerged. |
hotfix/* | Für kritische Fehlerbehebungen direkt auf main. Wird nach dem Fix auch in develop zurückgeführt, um Konsistenz zu wahren. |
3. Ablauf im Gitflow-Modell
- Feature-Entwicklung Ein neues Feature wird in einem eigenen Branch entwickelt:
git checkout -b feature/loginNach Fertigstellung wird es indevelopintegriert:git merge feature/login - Release-Vorbereitung Wenn ein Release ansteht, wird ein
release-Branch ausdeveloperstellt:git checkout -b release/v1.0Nach finaler Prüfung wird dieser inmaingemerged und getaggt:git tag v1.0Anschließend wird er auch indevelopzurückgeführt, um dort den Stand zu aktualisieren. - Hotfix bei Fehler Bei einem kritischen Bug wird ein
hotfix-Branch direkt ausmainerstellt:git checkout -b hotfix/critical-bugNach dem Fix wird er inmainunddevelopgemerged, damit beide Zweige den korrigierten Stand enthalten.
4. Vorteile von Gitflow
- Klare Trennung von Entwicklungsphasen Feature-Entwicklung, Release-Vorbereitung und Fehlerbehebung sind sauber voneinander getrennt – das erhöht die Übersichtlichkeit und reduziert Fehler.
- Stabilität der Hauptversion (
main) Nur getestete Releases landen inmain. Das schützt die produktive Version vor ungewollten Änderungen. - Parallele Entwicklung ohne Konflikte Mehrere Entwickler:innen können gleichzeitig an verschiedenen Features arbeiten, ohne sich gegenseitig zu stören.
- Rückverfolgbarkeit durch Tags Jede veröffentlichte Version wird getaggt (z. B.
v1.0), sodass man jederzeit nachvollziehen kann, welcher Code zu welcher Version gehört.
Aufgabe – Dein erstes Projekt mit Git und GitHub
Schaue dir folgendes Video an und führe anschließend die Aufgaben aus:
Schritt 1: Einrichtung der Arbeitsumgebung
- Installiere Visual Studio Code: Lade den Editor von der offiziellen Website herunter und installiere ihn.
- Installiere Git: Lade das Versionsverwaltungssystem Git von der offiziellen Website herunter und installiere es. Stelle sicher, dass du bei der Installation die Option wählst, Git in der Kommandozeile und in VS Code verfügbar zu machen.
- Erstelle einen GitHub-Account: Registriere dich kostenlos auf der GitHub-Website.
Schritt 2: Lokales Projekt erstellen und verwalten
- Öffne Visual Studio Code und erstelle einen neuen Ordner für dein Projekt.
- Öffne das Terminal in VS Code (Ansicht > Terminal oder
Strg+Ö). - Initialisiere ein lokales Git-Repository in deinem Projektordner, indem du den Befehl
git initin das Terminal eingibst. - Erstelle eine neue Datei in deinem Ordner (z.B.
README.md) und schreibe einen kurzen Text hinein. - Füge die neu erstellte Datei zur Staging-Area hinzu, um sie für einen Commit vorzubereiten. Nutze dafür das Source Control-Panel in VS Code oder den Befehl
git add README.mdim Terminal. - Erstelle deinen ersten Commit mit einer aussagekräftigen Nachricht, die deine Änderungen beschreibt (z.B. „Initialer Commit: README-Datei hinzugefügt“). Nutze dafür das Source Control-Panel oder den Befehl
git commit -m "deine Nachricht".
Schritt 3: Verbindung zu GitHub herstellen
- Gehe auf GitHub und erstelle ein neues leeres Repository mit dem gleichen Namen wie dein lokales Projekt. Klicke nicht auf die Option, eine README-Datei zu erstellen.
- Kopiere den Remote-URL-Link des leeren GitHub-Repositories.
- Füge den Remote-Repository-Link zu deinem lokalen Projekt hinzu, indem du das Terminal in VS Code nutzt. Die genauen Befehle findest du im Video.
- Pushe deine lokalen Commits auf dein GitHub-Repository, damit sie online sichtbar sind. Bestätige anschließend auf GitHub, dass deine Dateien hochgeladen wurden.
Schritt 4: Gemeinsame Arbeit simulieren
- Erstelle einen neuen Branch mit einem passenden Namen (z.B.
feature/neue-Funktion). - Wechsel in diesen neuen Branch und nimm eine kleine Änderung an deiner Datei vor oder füge eine neue Datei hinzu.
- Erstelle einen neuen Commit für diese Änderung.
- Pushe diesen neuen Branch auf GitHub und erstelle dort einen Pull Request.
- Wechsle zurück zum Hauptbranch (
main) und merg deinen Pull Request, um die Änderungen in den Hauptzweig zu integrieren.
Verständnisfragen
Beantworte die folgenden Fragen, um dein konzeptionelles Verständnis der im Video gezeigten Konzepte zu überprüfen.
- Erkläre in eigenen Worten den Unterschied zwischen Git und GitHub. Welche Rolle spielt jeder von ihnen in einem Softwareprojekt?
- Was ist die Funktion eines Commits? Welche Informationen enthält er und warum ist die Commit-Nachricht so wichtig?
- Beschreibe den Zweck der Befehle
git addundgit commit. Warum sind es zwei separate Schritte? - Erkläre das Konzept eines Branches. Warum würden Entwickler in einem Team Branches verwenden, anstatt alle Änderungen direkt im
main-Branch vorzunehmen? - Was ist der Unterschied zwischen den Aktionen
pushundpull? - Angenommen, du möchtest ein existierendes Projekt von GitHub herunterladen, um daran zu arbeiten. Welchen Befehl würdest du dafür verwenden und was macht er genau?